We don't need to compromise on freshness in retrieval
Here’s why I’m excited about TopK’s semantic_index, as someone coming from the recommender-systems community.

Whether you’re building search or recsys, the results your users see always start at the retrieval layer. And the hardest places to do retrieval tend to be hard for the same reason: the catalog never sits still. New items pour in constantly, existing ones change, and anything more than a few hours old is often dead weight. News feeds, social platforms, marketplaces — freshness isn’t a nice-to-have, it defines the product.
In general, any large-scale retrieval system needs three things:
- A way to ingest (and re-ingest) and index (and re-index) the whole dataset at scale
- Scalable query serving — high QPS, low latency
- High recall (of course)
You might say current solutions already do all three — and you’re right. But they get there by trading off cost and freshness. To hit quality, you serve the biggest embedding model you can find (accepting low write throughput or higher cost), then build an index on top — which means waiting before data is queryable. Worst case, you run expensive embedding jobs only to still end up serving stale data.
Where the quality actually comes from
semantic_index is different because freshness was never something we were willing to compromise on. Looking at the system as a whole, we found another way: carefully co-designing the core components — the model, the inference engine, and the database.
Half the issue, we realized, is relying on a large model to produce a single dense embedding, only to then use simple cosine similarity at query time. There’s more and more work showing this leaves quality on the table — one dense vector can’t capture enough detail — and that smaller models with a more expressive similarity function (late interaction, MaxSim) can match or beat much bigger ones.
The understated consequence: a smaller model shifts the cost balance in your system. It’s easier to scale write throughput, but each query gets more expensive. Not a free lunch — but it eases the first freshness bottleneck, slow writes. Which makes the second half, scalable querying without indexing lag, even more pressing.
Putting the index on the outside
Our answer was a radically different representation, which we call SMVE: vectors that expose an index structure on their exterior, instead of building an index post-hoc on top of dense vectors.
A new entry is transformed on write into a form that clicks into the existing index. No rebuilds, no lag — you write, and it’s there, ready to retrieve.
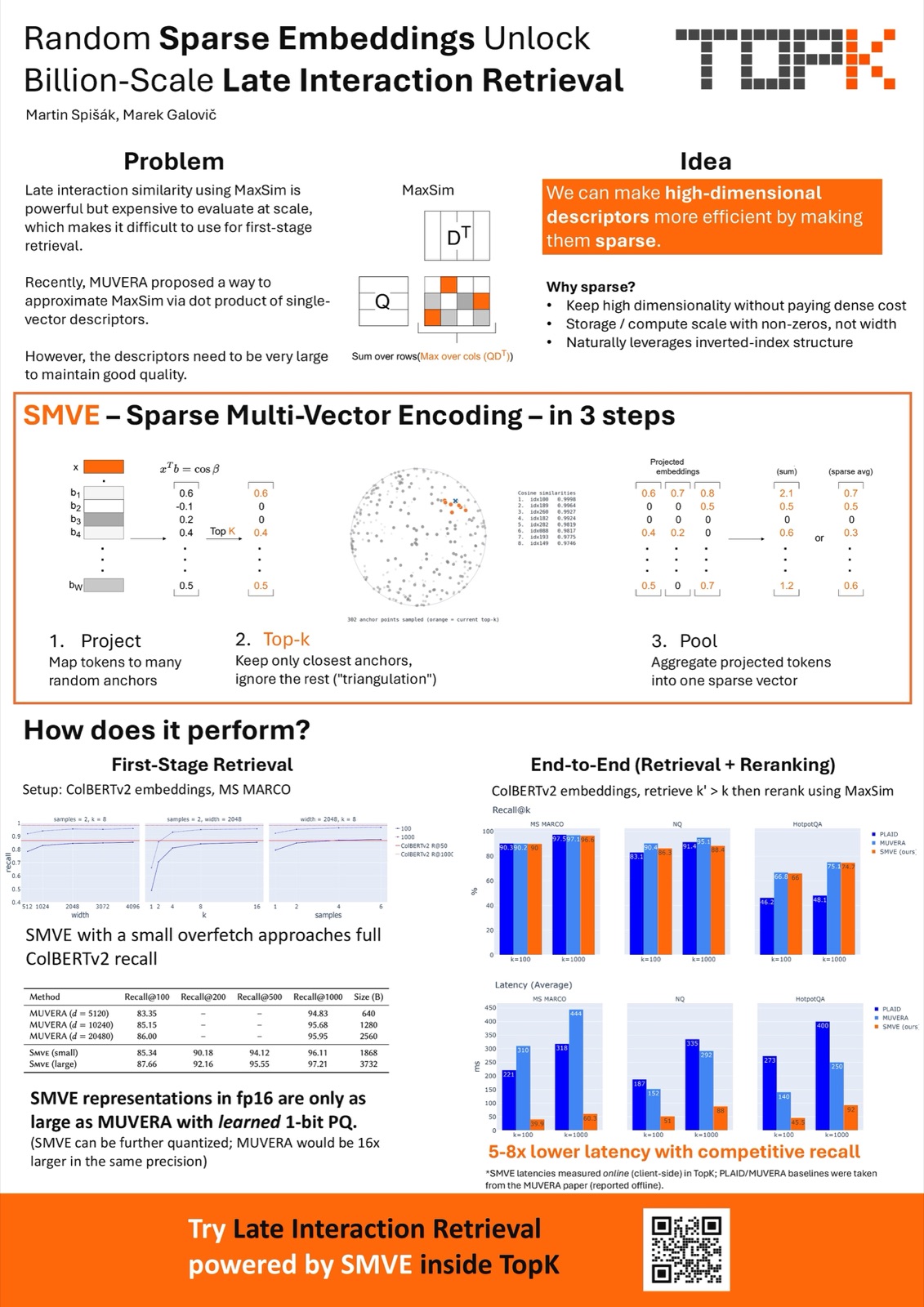
That’s the whole reason I’m excited: this design gives you all three requirements plus the freshness that makes a product feel alive. If freshness matters in your retrieval, don’t sleep on this one.
Going deeper: I wrote up the encoding itself in SMVE: Multi-Vector Retrieval That Just Works, the full system in High-Quality Search, Out of the Box, and the model that makes the sparse first stage hold up is Iso-ModernColBERT.