Late interaction has no LIMIT
A new embedding model just dropped — mixedbread’s wholembed-v3 — and the release made a big deal of its score on the LIMIT benchmark. That framing bugged me — so I went and checked. Here’s the short version: LIMIT is embarrassingly easy for just about any late-interaction (multi-vector) model.
First, a disclaimer, because I want to be fair: the model itself looks genuinely strong. What I don’t love is the emphasis on LIMIT. It’s the first thing in the announcement, and yet the result isn’t surprising given the right context — and it’s arguably not even a relevant measure of the model’s strength.
What LIMIT actually tests
LIMIT (arXiv:2508.21038) is a synthetic dataset built around token- and pattern-matching. On its own terms, that’s a reasonable thing to test: can a representation latch onto specific factual details? Fine.
The paper’s main point — that cramming many details into a single dense vector has limits — is fair. But the conclusion it draws about multi-vector models leans on results from exactly one model, GTE-ModernColBERT-v1, and that model does surprisingly poorly.
Why “surprisingly”? Because the task is essentially keyword detection. Late-interaction scoring via MaxSim does token-to-token matching — for each query token it picks the closest document token. That’s almost the ideal mechanism for this job: find the matching tokens, ignore all the distracting ones. A multi-vector model struggling here is the opposite of what you’d expect.
So I reproduced it
I tried to reproduce the reported Recall@100 for GTE-ModernColBERT (54.8%), and threw in a few other popular late-interaction models while I was at it — because why not. The notebook is deliberately tiny, five cells, optimizing for clarity over speed: limit_colbert.ipynb.
The numbers I got are very far from the paper’s, and they point the other way: multi-vector models look well-suited to this task, not hobbled by it.
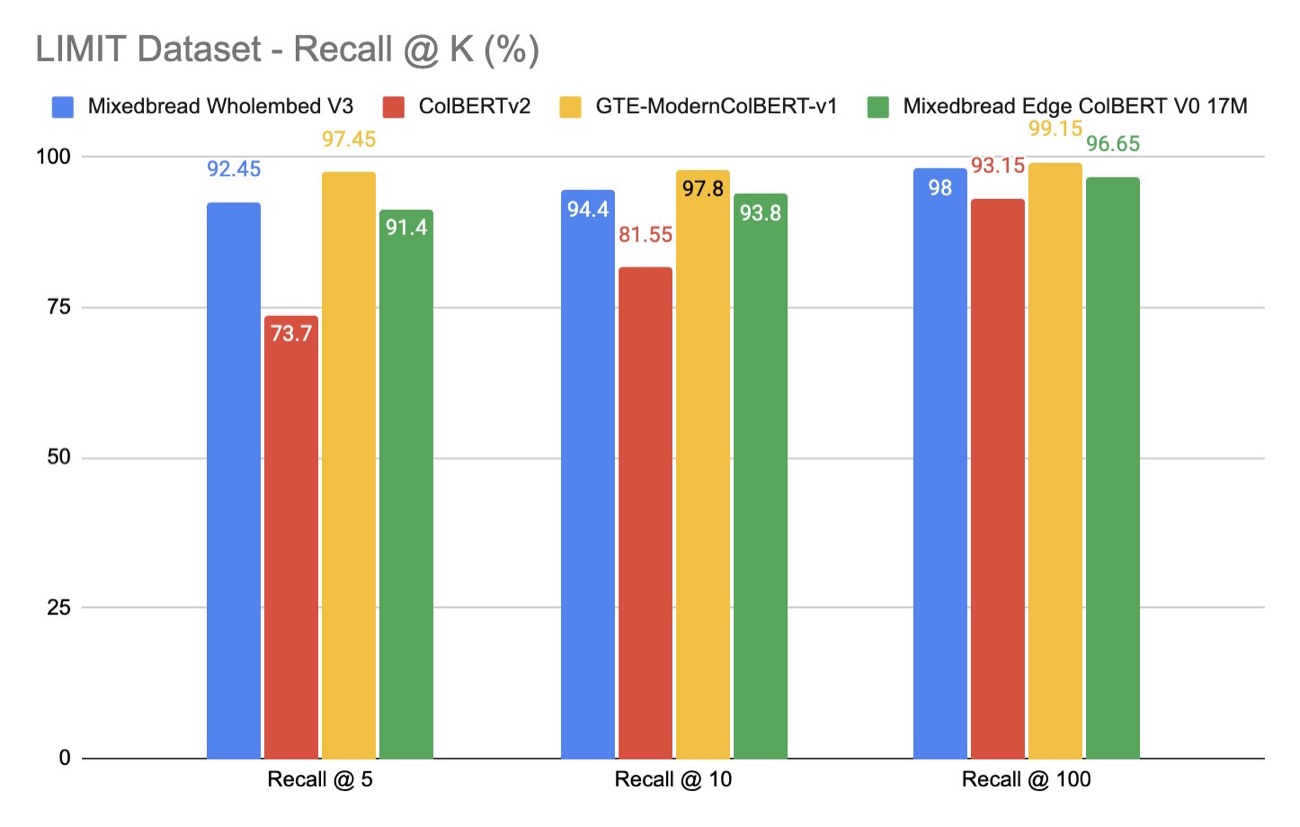
I’ll add the obvious caveat — even though I’m not satisfied with this slice of the evaluation, the release results overall are convincing and the model looks strong. Research is complex.
A detour about knives
Let me make the real point with an analogy. Pretend, for a minute, this is about knives instead of embeddings.
Knives get used for all sorts of things, but mostly cooking — so there’s a huge market for versatile kitchen knives. Chef’s knives. It makes sense that consumer comparisons test knives on kitchen prep: slicing bread, dicing onions, filleting fish.
But there’s another group of buyers whose needs are far more precise. Surgeons use scalpels — because doing surgery with a chef’s knife is a bad idea. To choose a scalpel, a hospital’s procurement team cares about its performance on, say, a cataract-surgery task.
Back to embeddings:
- Single-vector models are chef’s knives. If you need one model to cover everything, they’re your best bet.
- BM25 is a scalpel. More precise, less versatile — and it’s not obvious how to extend it beyond text.
- Multi-vector models are a hypothetical combination of the two: versatile like single-vector, but with much higher precision thanks to the rich MaxSim operator.
Here’s what I think the release actually demonstrates, and it’s a real result: it’s possible to get both versatility and surgical precision in one model. mixedbread forged the combined knife, and it performs strongly across a whole range of tasks. That’s genuinely impressive, and it’ll get more people to try multi-vector representations — which I’m all for.
But outperforming chef’s knives on a cataract-surgery benchmark won’t impress eye surgeons.
That’s all.