The future is sparse: compressing embeddings with CompresSAE
Vector databases are getting huge — and sparse embeddings are here to help.

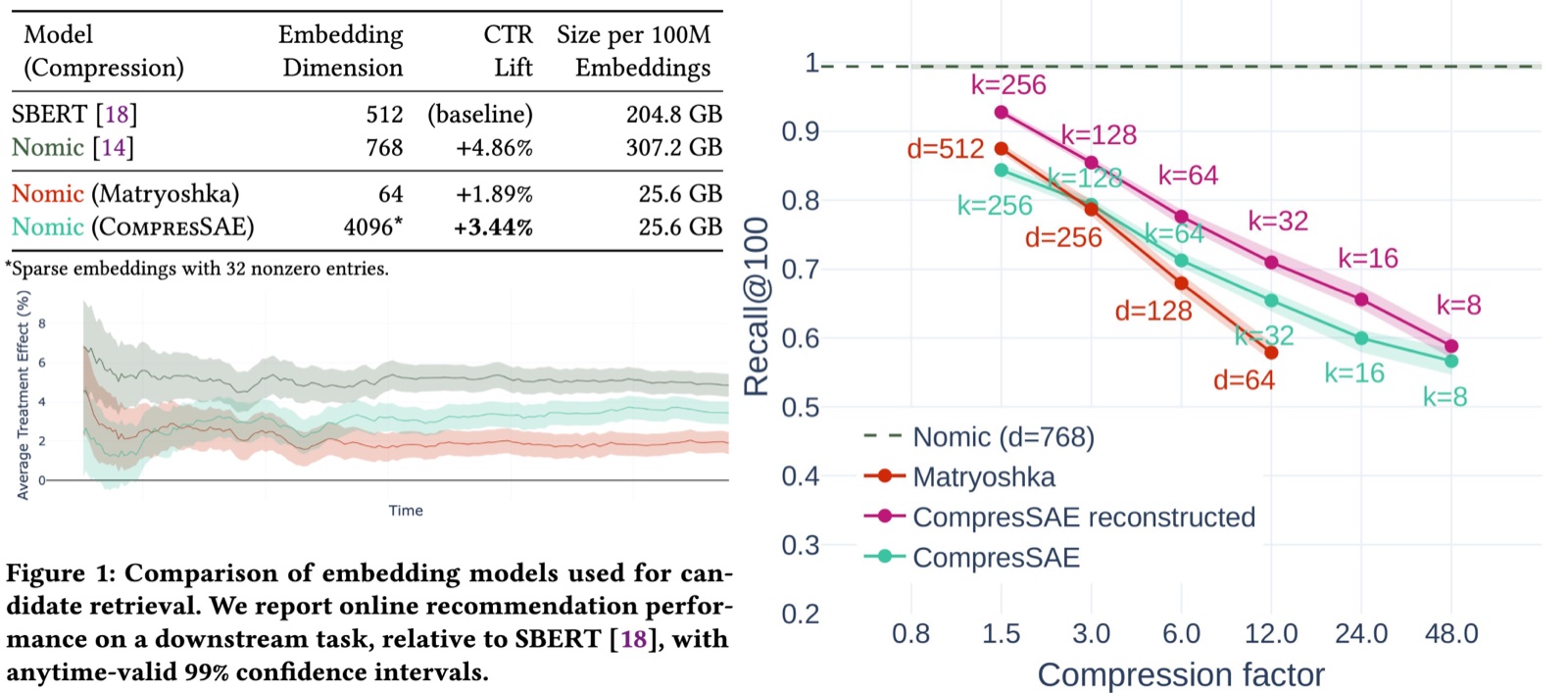
Embedding databases with hundreds of millions of vectors are nothing new in industrial recommender systems, but serving them at that volume remains costly and strenuous. To ease that strain, our team at Recombee developed CompresSAE: a lightweight, highly scalable embedding compression technique based on a novel sparse autoencoder (SAE).
The idea in one paragraph
With CompresSAE, reducing your embedding footprint by more than 10× — with only a small trade-off in downstream retrieval quality — can be as simple as:
- Train a lightweight SAE on embeddings already sitting in your vector database.
- Use the trained SAE encoder to transform your dense embeddings into a compressed sparse format.
- Serve them with a vector database that supports sparse vectors, and retrieve with standard cosine similarity.
No exotic serving path, no new similarity function — the compressed vectors drop into the infrastructure you already run.
Why it matters
Our results show a favorable compression–quality trade-off in real production deployment. That’s the part I find most interesting: it challenges the default assumption that large-scale vector search has to mean dense embeddings. For a lot of systems, the dense vector is carrying far more bits than the retrieval task actually needs.
The same idea travels beyond retrieval. We later used the sparse-autoencoder trick to surface segment-level insights for real-time editorial support across a news media group — Segment-Aware Analytics for Real-Time Editorial Support in Media Groups, which builds directly on CompresSAE.
We presented CompresSAE as a Spotlight talk at RecSys 2025.
- Paper: arXiv:2505.11388
- Code: github.com/recombee/CompresSAE
- Talk: The Future is Sparse — RecSys 2025
Big shout-out to the team at Recombee who made CompresSAE happen: Petr Kasalický, Vojtěch Vančura, Daniel Bohuněk, Rodrigo Alves, and Pavel Kordík.